条文本

文摘
客观的荟萃分析是基本重要的获得一个无偏评估可用的证据。一般来说,荟萃分析的使用一直在增加在过去三十年与心理健康作为主要研究课题。然后必须了解其方法和解释其结果。在这份出版物,我们描述如何执行一个荟萃分析的免费R统计软件环境,使用一个工作示例来自心理健康领域。
方法R包元是用来进行标准的荟萃分析。敏感性分析为失踪的二进制结果数据和潜在的选择性偏差进行metasens R包。提供所有必要的R命令并明确描述进行分析和报告。
结果工作示例认为一个二进制的结果:我们展示如何进行固定效应和随机效应分析和亚组分析,产生一个森林和漏斗图和测试和调整漏斗图不对称。所有这些步骤工作类似的其他结果类型。
结论R代表一个强大而灵活的工具进行荟萃分析。这份出版物简要了解主题和方向提供更高级的荟萃分析方法在R。
来自Altmetric.com的统计
介绍
证据合成是决策的基础,在一个大范围的应用程序包括医学、心理学和经济学。1系统评价和荟萃分析统计方法结合的结果是基石产生无偏评估可用的证据。2一般来说,荟萃分析的使用一直在增加在过去三十年与心理健康作为主要研究课题,例如,在科克伦评论。3
免费的R统计软件环境4(https://www.r-project.org)和商业软件占据5提供最大的荟萃分析的统计方法。RStudio (https://www.rstudio.com/)是一种流行,强烈推荐集成开发环境为R为策划提供菜单驱动的工具,以前的历史R命令、数据管理和R的安装和更新包。
介绍与占据已经发表在荟萃分析循证心理健康6与特定的关注行为的挑战和解释的荟萃分析结果数据时失踪,当发生小型研究的影响。
在这份出版物,我们复制这些分析R中的元使用包7和metasens。8
在下面,我们现在R命令:
安装R包进行荟萃分析。
进行荟萃分析,兴趣是二进制的结果。
评估丢失的结果数据的影响。
评估和考虑小型研究的影响。
方法
在进行分析之前,R包元metasens需要安装,9包括所有的功能来执行创建数据分析和提出了出版。
英斯达ll.packages (c (”元”,”metasens”))
使用第一个R命令,我们想要提到三个R命令的一般性质。首先,我们使用括号来执行一个R函数,在这里安装l.packages ();命令安装l.packages(没有括号)将显示函数的定义。第二,R函数的参数可以是另一个R函数;这里我们使用函数c ()结合R包的名字。第三,函数参数之间用逗号分隔,调用的函数是可见的c ()。RStudio用户也可以通过菜单:安装包工具- >安装包…
的图书馆函数可以用来使R包在当前会话可用:
库(元)
库(metasens)
一个简短的和非常有用的概述R包元提供的命令帮助(元)。在其他事情中,提到我们可以使用概述settings.meta函数定义默认设置为当前会话。在这份出版物,我们想打印所有结果与两个有效数字:settings.meta(数字=2)。
本文中使用的数据来自一个Cochrane综述评估的影响氟哌啶醇治疗精神分裂症的症状。10它已经被用来评估缺失数据对临床结果的影响11并在Chaimani作为工作的例子等。6氟哌啶醇与安慰剂相比,它由17个试验结果的兴趣是选择测量的临床改善和协会风险比率(RR),与RR大于1意味着氟哌啶醇比安慰剂。
每个试验的信息,连同第一作者的名字(作者)和出版年(一年),是:
参与者的数量在氟哌啶醇的手臂回应(resp.h)和对照组(resp.p)。
参与者的数量未能回应氟哌啶醇臂(fail.h)和对照组(fail.p)。
参与者退出的数量,结果是失踪,在臂(drop.h,drop.p)。
裁判中包含的数据集10可在在线补充文件1与以下R命令可以导入,鉴于它是存储在会话R的工作目录:快乐=读. csv (”Joy2006.txt”)。
这个函数read.csv有几个参数;然而,我们只指定数据集的文本文件的名称。RStudio用户可以使用菜单导入数据集:从文本文件- >导入数据集- >(基地)…在RStudio,默认情况下,R数据集的名称没有扩展文件名是一样的。因此,必须将数据集的名称设置为“快乐”导入向导以运行后续R命令。
一个新的R对象快乐创建可以被简单地键入:快乐。
或者,我们可以看到表格中的数据格式:视图(快乐)。
或得到的概述数据的结构(如类、维度清单和变量的格式):str(快乐)。
一些研究参与者与缺失的信息由于辍学(变量drop.h和drop.p)。之后,我们要进行亚组分析的研究并且不丢失数据,因此添加一个新的变量与这些信息数据集:
快乐$小姐=ifelse(快乐drop.h美元+快乐drop.p美元)= =0c (”没有缺失的数据”),c (”与缺失的数据”))。
一般来说,建议添加所有的变量,将用于分析的数据集进行荟萃分析。注意,我们访问一个变量在一个数据集使用美元符号。
R的一个全面的描述特性分析可以发现在泽等。9
固定效应和随机效应分析
感兴趣的结果,临床改善,二进制和提供的简要概述帮助(元)表明适当的R函数metabin。
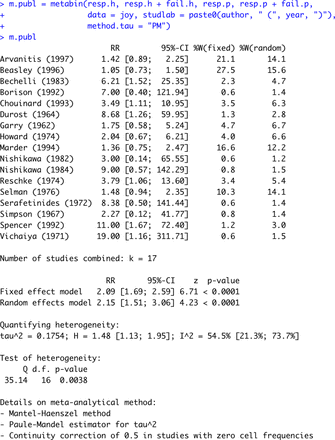
m.publ=metabin(职责。h, resp.h+失败。h,分别地。p,分别地。p+失败。p,数据=快乐,studlab=粘贴0(作者,”(”,年,”)”),方法。τ=”点”)
这个命令创建一个新的对象,命名m.publ包含几个组件描述的,这是一个列表的荟萃分析可以访问用户以最小的输入。默认情况下,RR用于metabin效果衡量,没有必要显式地指定该(可以设置参数吗sm=”RR”)。
第一个四个参数metabin是强制性的和定义变量包含病人的数量经历了临床改善和随机患者的数量(我们的信息),为实验的胳膊,控制臂,分别。函数执行固定效应和随机效应分析,12使用数据集快乐(论点数据)。这个论点studlab定义研究标签印刷在森林中所示的输出和情节,作为第一作者的名字,出版年。默认的方法来计算固定效应估计是Mantel-Haenszel。13方差倒数加权可以用于池通过指定方法=”逆”,这是用于Chaimani等。6之间的方差估计的方法可以指定在随机效应模型的参数method.tau;在这个例子中,我们选择的方法通过Paule和曼德尔,14这是一个二进制的推荐方法的结果。15
可以通过输入的结果m.publ或打印(m.publ)。第二个命令可以扩展到微调使用附加参数(见打印输出帮助(print.meta))。
我们使用下面的命令来生成森林场景:
森林(m.publsortvar=一年,预测=真正的,标签。离开了=”Favours安慰剂”,标签。正确的=”Favours氟哌啶醇”)。
只有第一个参数提供了分析对象m.publ是强制性的。这个论点sortvar订单研究根据指定变量的值,在这种情况下,通过增加年出版。这个论点预测=真正的表明,预测区间16应该显示在森林里的情节。的参数label.left和label.right指定标签印刷底部的森林图简化其解释。存在大量的附加参数修改(见森林阴谋帮助(forest.meta))。
评估丢失的结果数据的影响
为了理解如果研究缺失的数据不同于研究的结果没有缺失的数据,一个亚组分析可以通过命令:
m.publ.sub=更新(m.publbyvar=小姐,print.byvar=假)。
荟萃分析的对象m.publ更新和保存在一个新对象m.publ.sub。这个论点byvar表明分组变量小姐,上面添加到数据集。这个论点print.byvar用于抑制子群中的变量名的印刷标签。
探索丢失的结果数据结果的影响,提出了几种归责方法,11日17可用的函数metamissmetasens包。
在metamiss的观察与失踪的结果必须提供两个治疗组(在我们的示例中这些变量drop.h和drop.p)。指定的归责方法与参数method.miss,可能是下列之一:
”“大酒店””方法通过赌博和霍利斯。18
”IMOR”基于类属特异性的信息Missingness优势比(IMORs)。
”0”估算任何事件(即。,0)- - - - - -default method (Imputed Case Analysis (ICA)-0).
”1”估算作为事件(1)(ICA-1)。
”个人电脑”基于观察到的风险控制集团(ICA-pc)。
”体育”根据观察到的风险在实验组(ICA-pe)。
”p”基于类属特异性的风险(ICA-p)。
”b”最好的情况下实验组(ICA-b)。
”w”最糟糕的情形为实验组(ICA-w)。
例如,下面的命令将事件归咎于缺失的数据:mmiss.1=metamiss(m.publdrop.h,drop.p,method.miss=”1”)。
该方法通过赌博和霍利斯18个人研究是基于不确定性区间假设最好和最差情况下的丢失的数据。膨胀SEs计算不确定性的区间,然后考虑通用逆SEs的方差分析,而不是可用的荟萃分析。
所有其他的方法都是基于信息Missingness优势比(IMOR),定义为一个事件的几率在失踪组事件观察组的可能性11(例如,一个IMOR 2意味着一个事件的概率是假定为失踪的观察的两倍)。
为method.miss=”IMOR”IMORs在实验(论点IMOR.e)和对照组(论点IMOR.c)必须指定;如果两个值被认为是平等的,只有论点IMOR.e必须提供。对于所有其他方法的输入参数IMOR.e和IMOR.c忽略这些值取决于各自的归责方法(参见表2在裁判吗11)。它必须指定结果是否有益(论点small.values=”好”)或有害的(small.values=”坏”)选择最好的或最坏的场景时,也就是说,如果论点method.miss等于”b”或”w”。
评估和占小型研究的影响
有时小研究显示不同,往往较大,相比大的治疗效果。在荟萃分析规模和效果之间的关系被称为小型研究的影响。19
评估小型研究的存在影响的第一步通常是看看漏斗图,在衡量精度的影响估计,通常SE的影响估计。这可以通过函数funnel.meta荟萃分析的对象作为输入:漏斗(m.publ)。
一个不对称的漏斗图表明,小型研究存在影响。发表偏倚,但最受欢迎的,只有一个不对称的几个可能的原因。20.contour-enhanced漏斗图有助于区分如果不对称是由于发表偏倚,通过添加测试线代表地区的治疗效果是显著的。21为了生成这样的contour-enhanced漏斗图,论证contour.levels必须指定:漏斗(m.publcontour.levels=c(0.9,0.95,0.99),col.contour=c(”darkgray”,”gr一个y”,”浅灰色”))。
几个测试,通常被称为测试小型研究漏斗图不对称的效果或测试,提出了评估之间的联系是否估计效果和研究规模大于预期的机会。20日22这些测试通常有低功率,也就是说,即使他们不支持不对称性的存在,不能排除偏见。因此,他们应该使用只有包括研究的数量是10或更大。20.哈伯德评分测试,检验统计量是基于加权线性回归的有效得分,23应用于这个例子:metabias(m.publmethod.bias=”分数”)。
像往常一样,第一个参数是通过创建的对象metabin,而争论method.bias指定要使用的测试:”分数”哈伯德的测试。的metabias函数提供了一些其他方法测试漏斗图不对称(见帮助(metabias))。
一旦检测到存在不对称的漏斗图,还可以进行敏感性分析来调整估计这种偏见的影响。不同的方法存在22;在本文中,我们报告更成熟trim-and-fill方法24并通过回归的方法调整。25另一个更先进的方法是国王选择模型,26我们不治疗。
trim-and-fill方法,1)从漏斗图中删除/“修剪”研究直到它变成对称2)添加/删除“填充”镜像研究(即未发表的研究)最初的漏斗图和3)计算调整后的效果估计基于原始和补充研究。函数的应用trimfill:tf.publ=trimfill(m.publ)。
使用这个命令,创建一个新对象,命名tf.publ。可以通过输入显示的结果tf.publ或总结(tf.publ)得到一个简短的总结,可以创建一个相应的漏斗图:漏斗(tf.publ)。
“回归调整”的具体实现方法,叫做“限制荟萃分析”,裁判详细描述25。底层模型,出于症的测试,20.是一个扩展的随机效应模型与一个额外的参数α代表的小型研究影响(漏斗图不对称)通过允许治疗效果取决于SE。更明确,α预期的转变在标准化治疗效果如果精度非常小。模型提供了一个调整处理效应估计被解释为限制研究无限精确的治疗效果。图形化,这意味着增加了漏斗图曲线从底部到顶部,标志着调整处理效应估计。相应的函数limitmeta:l1.publ=limitmeta (m.publ)。
一个新对象,命名l1.publ创建。像往常一样,结果可以通过输入它的名字。漏斗图可以创建使用命令:漏斗(l1.publ)。
结果
R命令荟萃分析和敏感性分析已经在前一节中描述。为了生产这个发表的数据,我们稍微修改一些R命令之前介绍过的,不得不运行一些额外的计算。所有R命令用于执行这个section-including R的分析代码的数据就能被发现在线补充文件2。
固定效应和随机效应分析
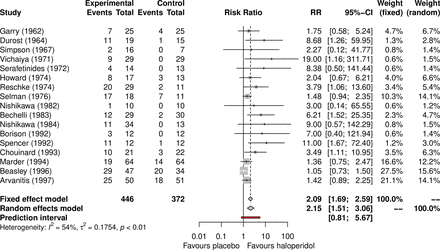
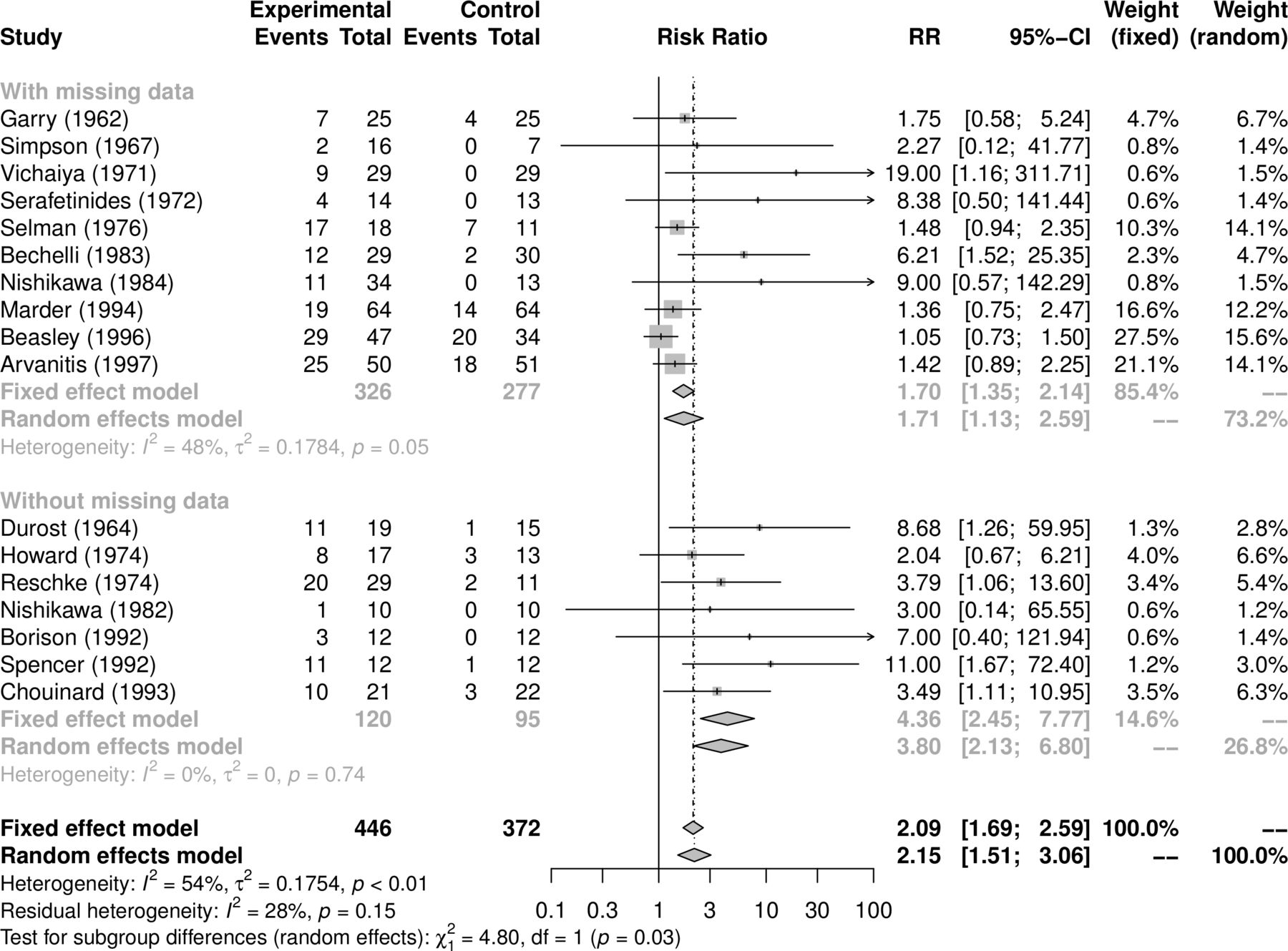
的metabin函数显示打印输出图1包含所有基本的荟萃分析信息(个人研究结果,固定效应和随机效应的结果,异质性信息和细节meta-analytical方法)。森林图显示的结果固定效应和随机效应分析中给出了考虑可用的情况下图2。两种模型,钻石呈现RRs估计和置信区间不越线的效果,表明氟哌啶醇明显比安慰剂更有效。然而,这个结果应该谨慎对待:预测区间,结合之间的异质性,穿过线没有影响,揭示安慰剂可能优于氟哌啶醇在未来的研究。
{kind=link}
{kind=link}
打印的metabin函数。
{kind=link}
{kind=link}
森林图显示的结果固定效应和随机效应分析(案例分析)。
一些独联体在森林里的情节不重叠,和异构性(p = 0.004)的测试也表明存在异构的结果。异构数据我2是54%,表明适度的异质性;CI范围从21%到74%,表示可能无关紧要的异质性(ref 13日9.5.2节)。13正如所料,总结的CI估计从随机效应模型是更广泛的比一个固定效应模型,但是这两个结果的大小稍有不同。
评估丢失的结果数据的影响
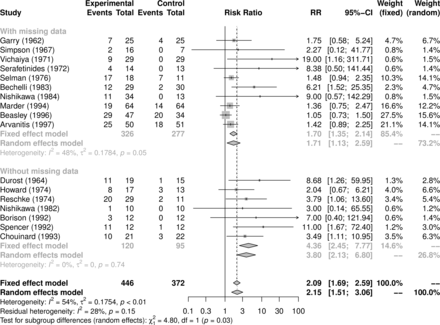
亚组分析的森林图存在缺失数据的研究中显示了图3。虽然两个子组给重要的结果,没有缺失数据研究报告相比更大的氟哌啶醇的作用与缺失的数据进行研究。并不是所有子群估计CIs包括各自的整体效果(微不足道的方式随机效应模型),和随机效应模型下的测试子组差异显示在森林阴谋支持视觉检测,表明缺失的数据可能会对结果有影响(p = 0.03)。一个原因可能是病人随机安慰剂更容易退出这项研究由于缺乏疗效与患者积极治疗的随机。如果这些患者失访,不良反应未见,治疗效果在这些研究被低估了。例如,两个研究(比斯利和塞尔曼)更多的失踪的观察在安慰剂组,而小治疗估计。
{kind=link}
{kind=link}
森林图显示存在缺失数据的亚组分析(案例分析)。
为了更好地理解如何缺失的数据可能会影响研究结果,提供更合适的方法metamissmissingness机制做出不同的假设。提出了随机效应模型的结果图4。总的来说,结果,而类似RRs从1.90到2.64的极端最差和最好的情况下。所有敏感性分析还表明,氟哌啶醇比安慰剂在改善精神分裂症的症状,说明丢失的结果数据并不是一个严重的问题在这个数据集。
{kind=link}

{kind=link}
总结风险比率根据不同假设missingness机制。
评估和占小型研究的影响
漏斗图所示图5(面板),固定效应模型由虚线表示的漏斗是集中的,而随机效应模型估计是用虚线表示。在我们的示例中,估计都是相似的;他们不能区分。漏斗图显然看起来不对称;然而,基于contour-enhanced漏斗图(图5面板B),发表偏倚似乎不像大多数小型研究不对称的主导因素与大型SEs躺在白色区域对应于非重要治疗估计。哈伯德的测试是非常显著(p < 0.001),支持小型研究效应的存在。
{kind=link}
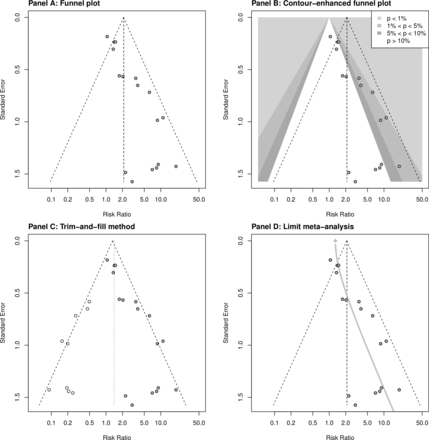
{kind=link}
漏斗图和各种方法来评估漏斗图不对称。
trim-and-fill方法增加了9个研究的荟萃分析(图5,面板C),导致调整随机效应估计RR = 1.40(0.83 - -2.38)表明氟哌啶醇与安慰剂比较的非重大的好处。
限制荟萃分析的结果所示图5,面板d .灰色曲线表明一些漏斗图不对称:开始(底部)相当大的偏差造成的随机效应估计小型研究和平衡这一点,接近一个点(顶部)留给随机效应估计,代表调整估计RR = 1.29(0.93 - -1.79),再次覆盖没有影响。
讨论
循证医学的荟萃分析是一个基本的工具,因此它必须了解其方法和解释其结果。现在几个软件选项可用来执行一个荟萃分析。在这篇文章中,我们旨在给出一个简要介绍如何进行荟萃分析在免费软件R使用meta和metasens软件包,它提供了一个用户友好的荟萃分析的实现方法。元数据包已经由过去的作者交流荟萃分析结果临床同事在Cochrane综述。
对于插图,我们使用一个二进制的结果和一个例子展示了如何进行荟萃分析和亚组分析,产生一个森林和漏斗图和测试和调整漏斗图不对称。所有这些步骤工作类似的其他结果类型,例如,Rmetacont可用于连续函数的结果。此外,我们为失踪的二进制结果进行了灵敏度分析Rmetamiss函数。
在我们的示例中,所有敏感性分析缺失的数据导致类似的结果支持氟哌啶醇的好处超过安慰剂missingness机制尽管非常不同的假设。然而,漏斗图不对称的评估显示小型研究效果根据contour-enhanced漏斗plot-cannot归因于发表偏倚。尽管所有敏感性分析调整治疗选择偏见导致与估计,我们不愿意解释这些结果太多的小型研究的临床异质性可能是另一种解释的效果。22更深的知识条件下研究中,治疗和设置的是它的管理在不同试验可以帮助识别可能的原因不对称的漏斗图。
在这份出版物,我们只能提供短暂的一瞥的荟萃分析的统计方法R .感兴趣的读者可以看到这份出版物作为起点为其他(更高级)分析方法可以在R R包的概述在网站上提供了荟萃分析https://cran.r-project.org/view=MetaAnalysis。我们想只简要提及两个R包从这个列表。R包metafor27是另一个总体方案分析,除了提供了多层次分析方法28以及多变量分析。29日R包netmeta30.实现了一个网络荟萃分析和频率论的方法是今天最全面的R包网络荟萃分析。
引用
脚注
贡献者某人起草手稿和执行分析;GR和GS批判性修订后的手稿和回顾了分析。
资金作者并没有宣布具体资助这项研究从任何公共资助机构,商业或非营利部门。
相互竞争的利益没有宣布。
病人同意出版不是必需的。
出处和同行评议不是委托;外部同行评议。