偏见在荟萃分析检测到一个简单的、图形化的测试
BMJ1997年;315年doi:https://doi.org/10.1136/bmj.315.7109.629(1997年9月13日出版)引用这个:BMJ315:629 1997;
- 马提亚症,读者在社会医学和流行病学(m.egger在{}bristol.ac.uk)一个,
- 乔治大卫史密斯临床流行病学教授一个,
- 马丁·施耐德,研究助理b,
- Christoph看守者单位负责人、医疗统计数据b
- 函授:Egger博士
- 接受1997年8月26日
文摘
摘要目的:漏斗图(块效应估计与样本大小)可能是有用的在荟萃分析来检测偏差,后来与大型试验。我们检查是否一个简单的测试不对称的漏斗图预测不一致当荟萃分析的结果与大型试验相比,我们出版的荟萃分析评估的流行的偏见。
设计:Medline搜索来确定对组成的荟萃分析和一个大型试验(一致性的结果是认为如果影响是在同一个方向和整合估计是在审判的30%);漏斗图分析来自37个荟萃分析发现从一只手搜索四个领先的通用医学期刊1993 - 6和38个荟萃分析从1996年第二期Cochrane系统评价的数据库。
主要结果测量:漏斗图不对称度的拦截标准正态回归的背离与精度。
结果:八双的荟萃分析和大型试验被识别(五从心血管医学,一个来自糖尿病药物,一个来自老年医学,一个从围产期医学)有四个整合和四个不和谐的对。在所有情况下不一致是由于荟萃分析显示更大的影响。漏斗图不对称有四分之三的不整合对但没有整合对。在14个(38%)杂志荟萃分析和5 (13%)Cochrane综述,漏斗图不对称表明有偏见。
结论:简单的漏斗图分析提供了一个有用的测试可能存在偏见的荟萃分析,但随着能力检测偏差时将有限的荟萃分析是基于有限的小型试验结果从这样的分析应该相当谨慎对待。
关键信息
系统评价的随机试验是评价证据的最佳策略;然而,后来被一些分析的结果与大型试验
漏斗区,试验的效果对样本量估计,倾斜和不对称的存在发表偏倚和其他偏见
漏斗图不对称,通过回归分析,预测不一致结果的荟萃分析与单一大型试验
漏斗图不对称被发现在38%的荟萃分析发表在领先的通用医学期刊和13%的评论Cochrane系统评价的数据库
系统评价的关键考试出版及相关偏见应该考虑例行程序
介绍
系统评价最好的现有证据关于医疗干预措施可以通知的益处和风险决策在临床实践和公共卫生。12这样的评论是,只要有可能,基于荟萃分析:“统计分析相结合或集成了几个独立的临床试验的结果被分析师认为是可以化合的。”3然而,后来被一些分析的结果与由大型随机对照试验。4对一项技术的这种差异产生了怀疑,自一开始就一直存在争议。5误导性的荟萃分析的出现并不奇怪考虑发表偏倚的存在和其他许多偏见,可能在定位的过程中,介绍了选择和结合研究。6789
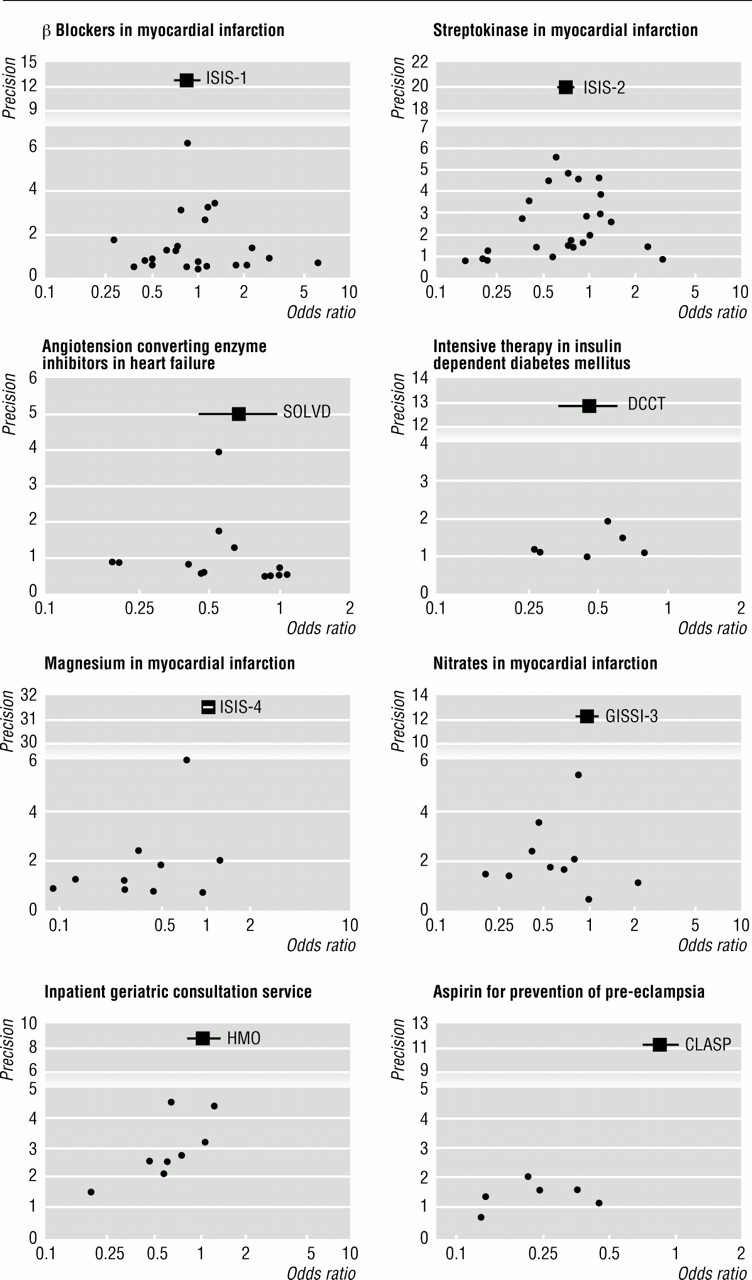
漏斗区,试验的效果对样本量估计,可能是有用的评估荟萃分析的有效性。410漏斗图精度评估是基于事实基础治疗效果会增加组件研究样本量的增加。从小型研究结果必将广泛分散在图的底部,与缩小在更大规模的研究。没有偏见的情节将像一个对称的倒漏斗。相反,如果有偏差,漏斗情节往往会扭曲和不对称。
漏斗图的价值还没有被系统地检查,和对称或不对称普遍非正式的定义,通过视觉检查。不出所料,漏斗图以不同的方式解释了不同的观察者。11我们测量漏斗图不对称数值并分析了这种不对称的程度预测不一致结果的荟萃分析比较单一的大型试验相同的问题。我们使用相同的方法来评估漏斗图不对称的流行,因此可能的偏见,在荟萃分析发表在领先的通用医学期刊和荟萃分析传播电子由Cochrane协作。
方法
漏斗图不对称的措施
我们使用了一个线性回归的方法测量漏斗图不对称优势比的自然对数的规模。这对应于一个回归分析加尔布雷斯的径向情节,12虽然在现在的环境下通过原点回归不受限。标准正态偏离(SND),定义为优势比除以它的标准误差,是退化对估计的精度,后者定义为标准误差的倒数(回归方程:SND =一个+bxprecision)。随着精度很大程度上取决于样本大小,小型试验×轴将接近于零。小型试验可能产生不同于统一的优势比,但由于标准误差会很大,由此产生的标准正态偏离再次将接近于零。小型试验从而将接近于零的两轴,接近原点。相反,大型研究将产生精确的估计,如果治疗有效,还生产大型标准正常的偏离。试验的同构集中的点,而不是扭曲了选择性偏差,将散射线贯穿原点在标准正态偏离零(一个= 0),斜率b指示作用的大小和方向。12这种情况下对应于一个对称的漏斗图。
如果有不对称,较小的研究显示效果,系统地从更大的研究不同,回归线不经过原点。截距一个提供了一个衡量asymmetry-the较大偏离零更明显不对称。如果小研究显示大的保护作用,他们将迫使下面的回归线原点在对数刻度。因此负值将表明,较小规模的研究显示比更大规模的研究更明显的有利影响。在某些情况下(例如,如果有几个小型试验,但只有一个较大的研究)是通过加权分析的逆效应的方差估计。我们进行加权和未加权的分析和使用分析的输出产生较大的拦截偏离零。
与异质性的整体测试,测试漏斗图不对称评估特定类型的异质性,在这种情况下提供了一个更强大的测试。然而,任何分析异质性的数量取决于试验包括荟萃分析,通常小,这限制了统计测试。因此我们不对称的证据基于P < 0.1,我们给拦截90%置信区间。同样的显著性水平已经使用在以前分析异质性的荟萃分析。1314
荟萃分析的识别和匹配大型随机试验
Medline搜索(Knight Ridder信息服务,伯尔尼,瑞士)覆盖周期执行1985年1月至1996年4月1996年4月确定出版的荟萃分析。为此“荟萃分析”这个词进入在一个自由的文本搜索。文章确定了包括所有这些索引与医学主题标目(网)关键字“荟萃分析”,这在1989年推出的时候,这个词和文章没有关键字进行荟萃分析在题目或摘要。结果被出版的来源列表,和物品刊登在期刊产生30或更多的关注进一步检查。荟萃分析的对照试验至少五个试验结合二进制端点被确定。
大规模的随机对照试验的干预后发表Medline搜索发现的荟萃分析是使用适当的关键词。大型试验的影响提供一个估计的精度至少5。例如,一个试验在心力衰竭患者的死亡率在对照组三个月是5%15和治疗患者的死亡率减少到3%需要随机选择2800例来衡量这种影响精度的5和12 000名患者的精度10。此外,效果估计的大型试验必须等于或比荟萃分析更精确。我们审查潜在匹配的成对的荟萃分析和大型试验对研究参与者,干预,结束点和长度的跟进。在某些情况下进一步Medline搜索进行识别分析发表在任何期刊索引Medline将更适合与大型试验进行比较。
几年前发表一些分析相应的大审判。在这些情况下我们检查漏斗图的形状是否改变了荟萃分析更新试验时在此期间发表。
一致性和冲突的结果
荟萃分析结果的比较和大型试验所需表达的结果在一个常见的规模。优势比被用于这一目的。荟萃分析和大型试验被认为是整合效应在同一个方向和荟萃分析的估计在30%的估计的单独审判。30%的差异提出了维拉等来表示高相似性荟萃分析的结果和大型试验。11
SAS 6.11版本软件包(统计分析系统,卡里,NC)是用于统计分析。
不对称的漏斗图的频率
我们执行一个搜索四个主要一般医学期刊,内科医学年鉴,BMJ,《美国医学会杂志》,《柳叶刀》,从1993年到1996年,研究了1996年第二期Cochrane系统评价的数据库16确定对照试验的荟萃分析。分析与分类是基于至少五个试验终点进一步检查。对于每个干预和比较,测量结果报告在被选最多的试验。获得一致性审查,终点记录如果有必要这样效果预期的方向有益的结果是在同一个方向。例如,在审查试验戒烟的尼古丁贴片,继续吸烟,而不是放弃被认为是结果,所以上面的优势比统一表示一个不利影响。
我们确定了38 Cochrane评论和37个荟萃分析》杂志上。所有引用的荟萃分析和试验包括可从作者的请求。
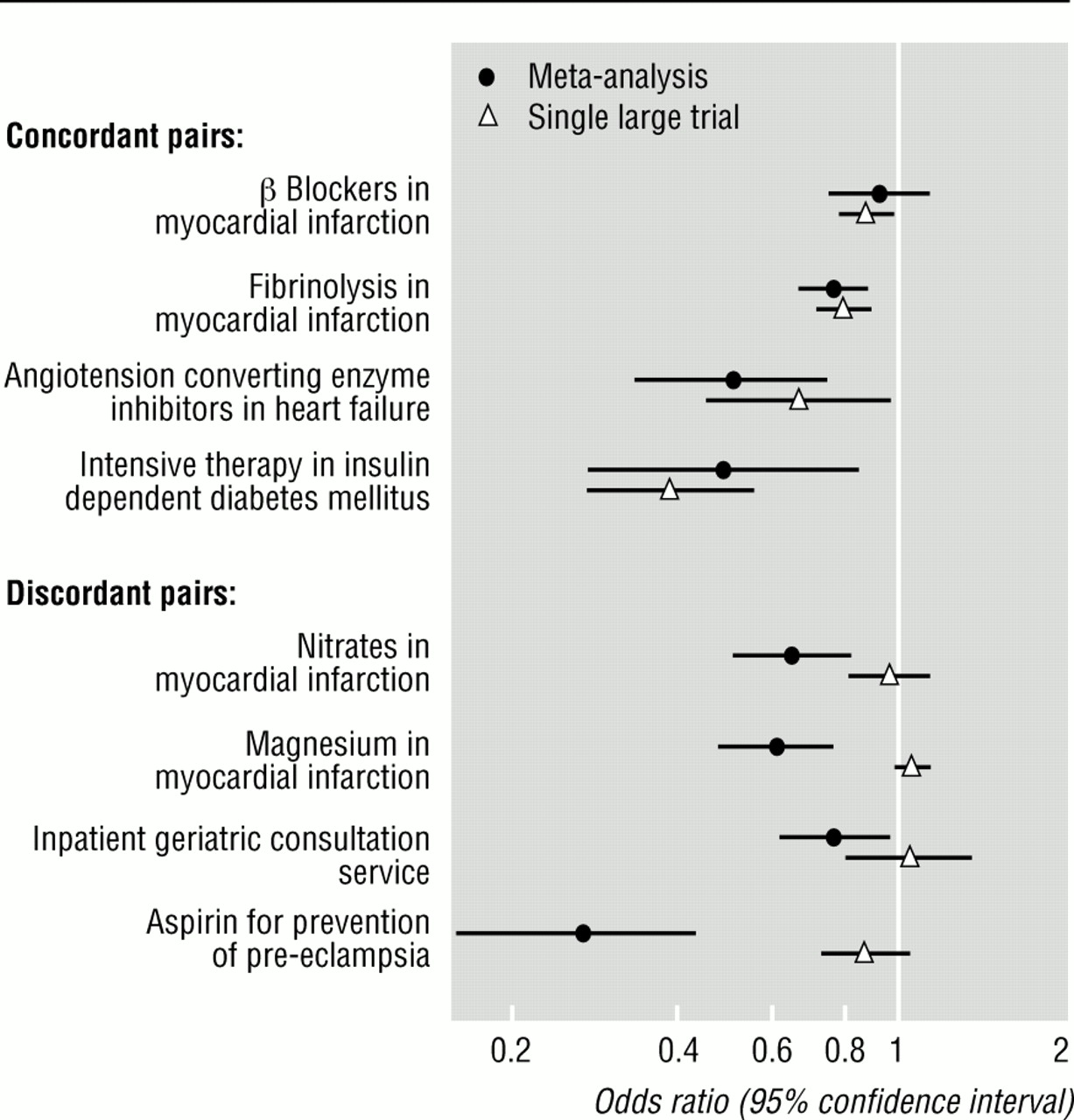
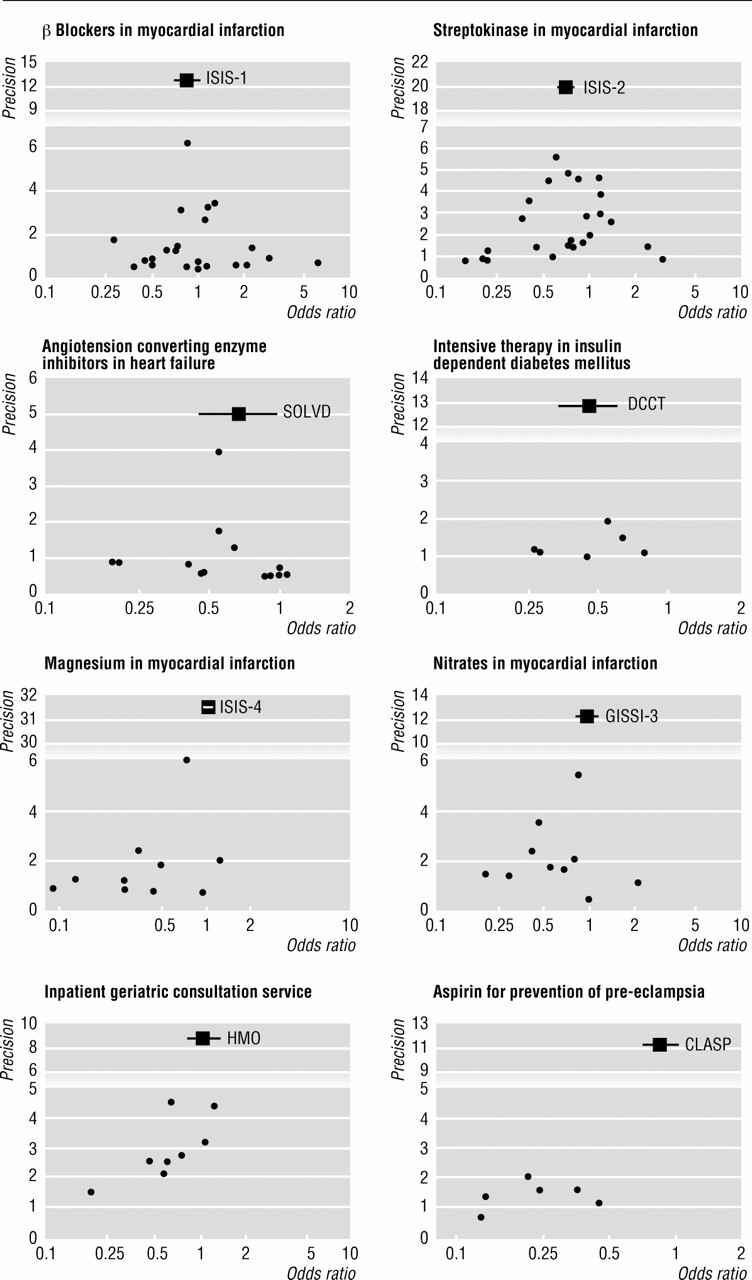
额外试验确定了三个荟萃分析出版几年前比大审判。262729日这是摘自最近的荟萃分析。431日32当试验的荟萃分析心肌梗死静脉镁的更新五个额外的拦截试验显示更大的不对称(−1.36 2.06(90%置信区间−−0.66),P = 0.005)。当13还添加了额外的试验来试验的分析血管紧张素转换酶抑制剂在心力衰竭情节仍对称(拦截0.07(−0.53到0.67),P = 0.85)。当分析阿司匹林预防先兆子痫的更新与九额外试验,漏斗图成为不对称(拦截−1.49 (−2.20−0.79),P = 0.003)(图3)。

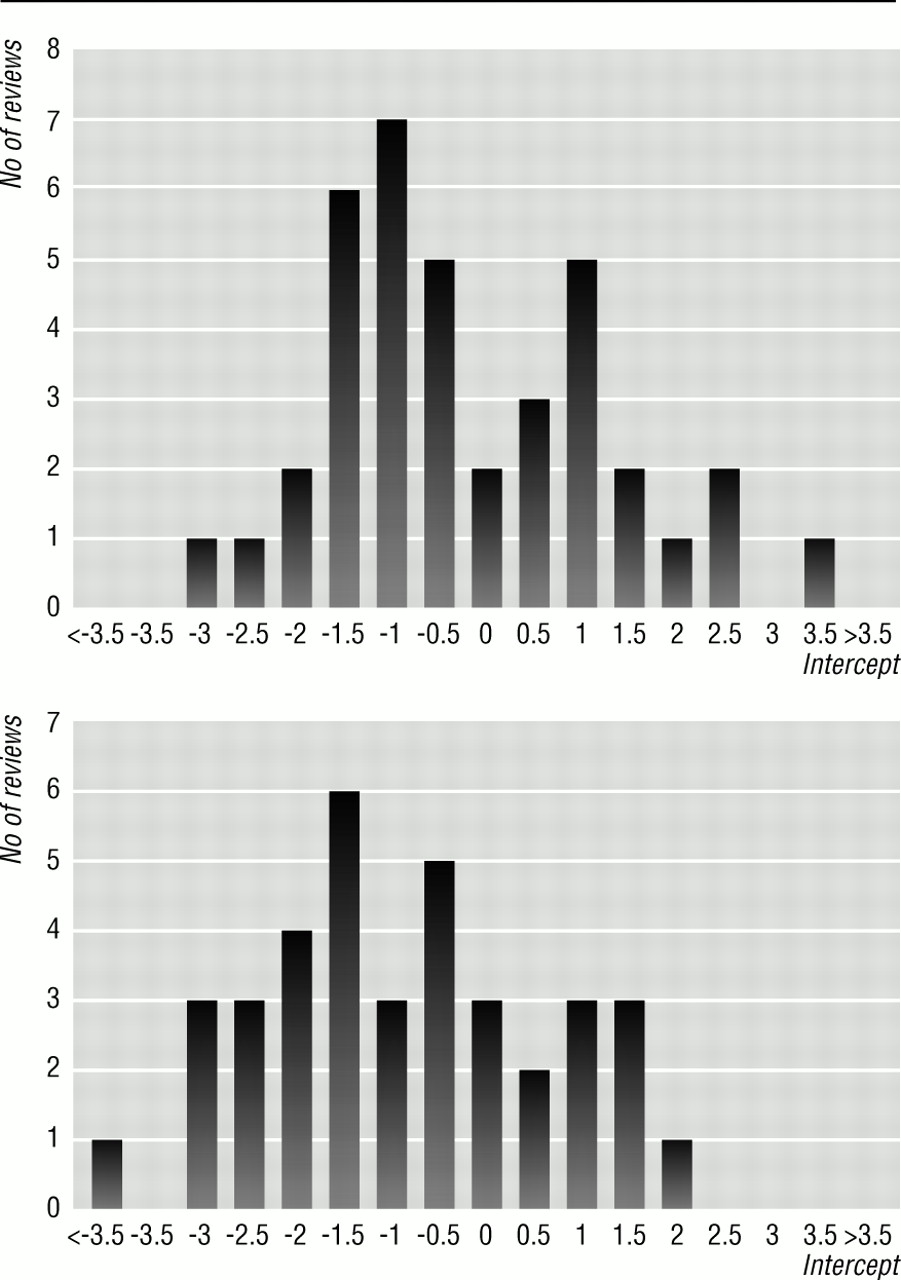
图4显示分布的回归拦截来自38个Cochrane评论和37个荟萃分析》杂志上。没有偏见,随机波动应该产生一个对称分布的拦截的核心价值为零,与同等数量的积极和消极的价值观。这不是观察的目标是什么。分布是转向负值,意味着−0.24(−0.65到0.17),科克伦评论和−1.00(−1.50−0.49)杂志荟萃分析有24 - 14正面拦截在Cochrane综述由符号检验(P = 0.10)和26 - 11正面拦截在杂志荟萃分析由符号检验(P = 0.007)。在五(13%)Cochrane综述和14(38%)杂志荟萃分析有显著(P < 0.1)不对称的证据。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
讨论
随机对照试验的选择性发布积极的发现是一个重要的问题在整合文献的评论。9如果文学更有可能包含试验显示出治疗的有利影响,如果同样有效试验显示没有影响仍未发表,系统评价的文献如何作为一个客观的决策指南在临床实践和卫生政策?发表偏倚的潜在的严重后果已意识到一段时间,也有反复呼吁全球临床试验登记在《盗梦空间》。14333435尽管注册试验和创建一个数据库控股发表和未发表的试验的结果将解决这个问题,不太可能在可预见的未来,这将是广泛建立。
关键检查出版物和相关偏见的存在必须成为整合研究的一个重要组成部分,系统的评论。这里给出的结果表明,一个简单的图形和统计方法是有用的。当测试这个方法对组成的荟萃分析和单一的大型试验相同的干预,我们发现不对称在四分之三的漏斗图对不和谐的结果。第四是基于只有6个试验,和不对称出现的时候更新进一步的研究。
漏斗图不对称的来源
发表偏倚一直与漏斗图不对称有关。10在已发表的研究中,然而,识别相关试验的荟萃分析的概率也受到他们的结果。英语重点优先出版的“负面”在期刊上的研究结果发表在除英语之外的其他语言的位置和包容这样的研究较少。8由于引用偏见,“负面”研究引用次数少,因此更有可能错过在寻找相关的试验。736“积极的”试验的结果有时会不止一次报道,增加他们的概率将位于荟萃分析(多个发表偏倚)。37这些偏见可能影响较小规模的研究更大程度比大试验。
不对称的另一个原因来自方法学质量的差异。平均,较小规模的研究和分析进行不如更大规模的研究方法严谨。低质量的试验也显示出更大的效果。383940漏斗图中的对称度可能取决于统计用来测量的效果。优势比高估的相对减少,或增加,如果事件风险率很高。41这可能导致漏斗图不对称,如果小试验都在病人进行更高的风险。类似地,如果事件积累以恒定速率,相对风险将走向统一长度的增加跟进。在大型试验,跟踪通常比小研究。最后,一个不对称的漏斗图可能出现的机会。
试验显示在一个漏斗图不可能估计相同的底层的干预,这样的结果之间的异质性可能会导致不对称的漏斗图。例如,如果一个组合的结果被认为是那么实质利益可能只有高危患者的组件组合的结果所影响的干预。42一种降低胆固醇的药物,可以降低冠心病的死亡率将有更大的影响在所有原因的死亡率比无症状高危患者建立心血管疾病患者孤立的鸡蛋。这是因为一个一致的相对降低冠心病的死亡率将会转化为更大的相对减少所有原因的死亡率在高危患者中,在他将更大比例的人死于冠心病。这将产生不对称的漏斗图,如果小在高危病人进行临床试验。
小型试验通常是建立前进行更大的试验。在随后的几年里,控制治疗可能改善或改变的方式可以减少实验治疗的疗效。这种机制提出了一个解释的矛盾的结果在临床试验中镁的影响灌注心肌梗塞,43虽然这个解释是不支持的临床试验的数据。44最后,实现了一些干预措施可能不彻底在较大的试验,从而解释了更多积极的结果在较小的试验。这可能发生在一个干预被认为是在我们的比较分析和单一的大型试验,住院老年咨询。14
非常不同的机制可以导致不对称的漏斗图,作为总结盒子。然而,重要的是要注意,这总是会被关联到一个有偏见的总体估计当研究结合在一个荟萃分析的影响。更明显不对称,越有可能是偏见的数量将是丰富的。这个规则的例外出现不对称时产生的机会。
不对称的漏斗图的来源
发表偏倚
位置偏差:
英语的偏见
引用的偏见
多个发表偏倚
真正的异质性
效应的大小根据研究不同大小:
强度的干预
潜在风险的差异
数据异常
可怜的方法论的小型研究的设计
分析不充分
欺诈
出土文物
选择影响测量
机会
偏见在荟萃分析有多频繁?
最近几项研究试图评估分析的有效性。道等分析了38个荟萃分析的妊娠和分娩模块1993 Cochrane数据库通过比较最大试验的结果与剩下的较小规模的研究。45的方向的基础上估计的治疗效果,他们得出结论,80%的荟萃分析在全部或部分协议的结果更大的“黄金标准”的审判。在类似的研究中,Cappelleri et al 79荟萃分析和得出结论,分析小型试验和大型试验之间有协议在80%以上。13然而,在这两种分析,大型试验的精度很低在比较中占据相当大的比例。更大的试验通常实际上提供了一个估计的精度低于小研究的荟萃分析。在这种情况下,两者之间的一致性也可能是由于这样的事实,与大估计,置信区间重叠不太可能被归类为不整合。46
我们认为严格的标准是必要的标识可以被明智地使用单一的大型试验评估小型试验的荟萃分析的结果。因此,我们的分析中使用的大型试验平均提供了一个估计的更大的精度,相应的荟萃分析。尽管一个广泛的文献检索,我们发现只有八个这样的对。因此匹配配对方法可能不适合评估误导荟萃分析的频率。然而,我们的研究结果表明,不对称的漏斗图使偏见的可能性。漏斗图不对称的患病率可能因此提供一个有用的代理措施检查偏差分析的文献的患病率。我们的发现表明偏见可能出现在一个小比例的荟萃分析发表在Cochrane系统评价的数据库。偏见可能会更加普遍,然而,在荟萃分析发表在领先的通用医学期刊。这种偏见可能影响系统回顾和荟萃分析的结论必须仔细评估每个案件。
贝格和Mazumbar提出等级相关测试来测量不对称的漏斗图。47方法是基于关联程度的大小影响及其方差的估计。如果存在发表偏倚,较小规模的研究将会显示更大的影响。之间的正相关效应值和方差出现在这种情况下,因为估计的方差较小规模的研究也会大。当我们测试应用于八个荟萃分析,这表明显著(P < 0.1)只有一个荟萃分析不对称(住院老年咨询14)。这表明线性回归方法可能更强大的比等级相关测试。
结论
没有大的,确凿的试验对大多数医疗干预措施,基于随机对照试验的系统评价为评价证据显然是最好的策略。选择性偏差和其他偏见对这种方法的有效性构成严重的威胁,然而,必须注意避免荟萃分析成为名誉扫地。这里讨论的技术应该为这一目标,提供可再生的测量可能存在的或明显的缺失,这种偏见。它很容易计算和提供摘要统计信息时,可以报道空间限制不允许显示漏斗的情节。虽然需要更多的方法论的研究,出版和相关的关键考试存在偏见应该考虑一次例行程序。能力发掘这种偏见,然而,是有限的,当荟萃分析仅基于小型试验。没有统计的解决方案在这种情况下,这种分析的结果应该谨慎对待。
确认
我们感谢安德烈亚斯卡吉尔伯特拉米雷斯请提供额外的数据。
资金:瑞士国家科学基金会(授予3200 - 045597和3233 - 038803年)。
利益冲突:没有。